Back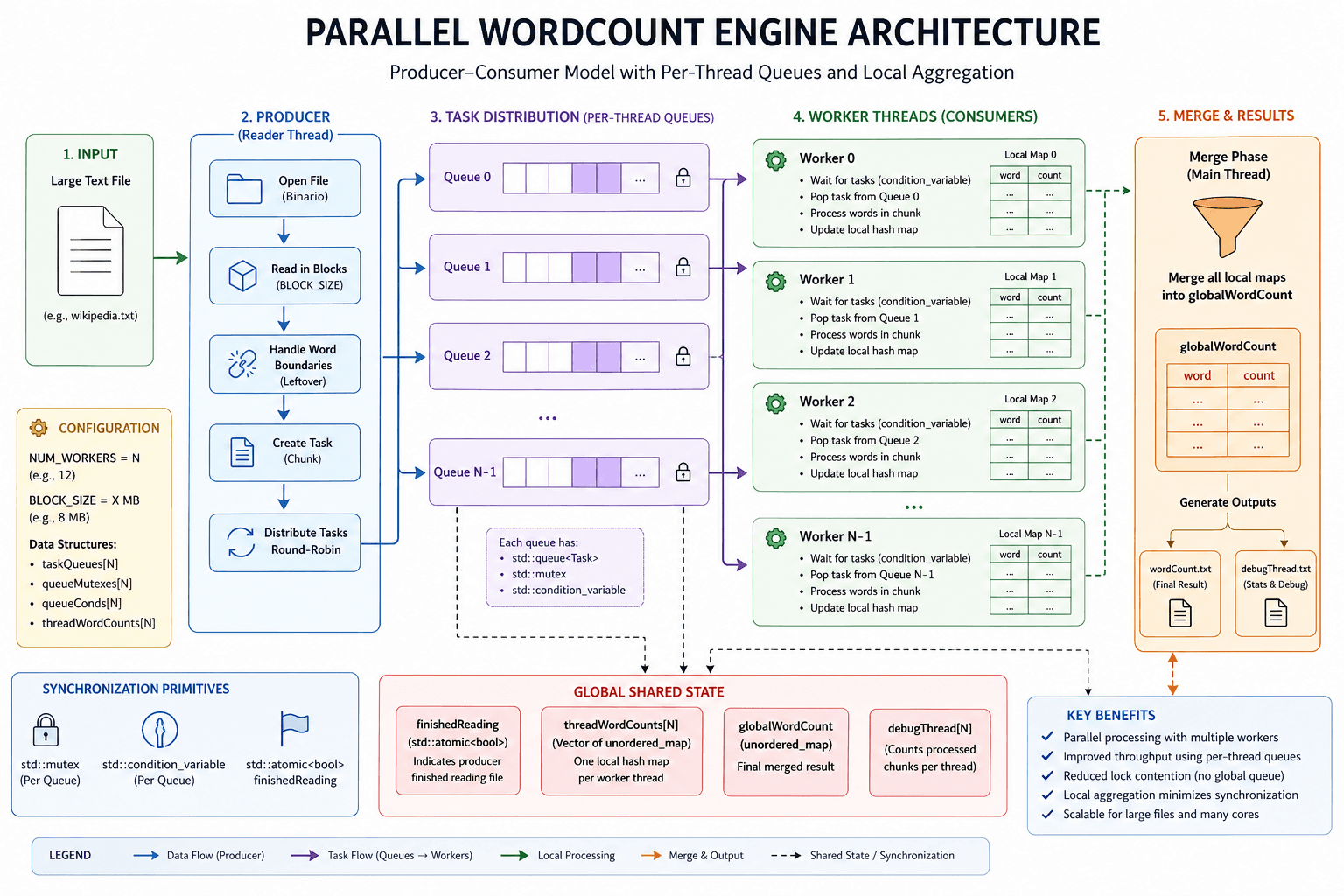






Parallel WordCount Engine in C++
01
Overview
- Proyecto desarrollado en C++ para implementar desde cero un sistema de WordCount orientado al procesamiento eficiente de archivos de gran tamaño sin utilizar frameworks externos como Hadoop o Spark.
- El sistema utiliza arquitectura Producer-Consumer con múltiples hilos de trabajo para procesar bloques de texto en paralelo y reducir el tiempo total de ejecución.
- El objetivo principal fue optimizar concurrencia, uso de memoria y throughput en escenarios de Big Data reales.